




Abstract
The polygenic risk scores (PRS) have emerged as a transformative approach for quantifying inherited
predisposition to complex diseases, leveraging the unprecedented expansion of genome-wide association
studies (GWAS) and advances in statistical genetics. By aggregating the marginal effects of millions of
common variants, PRS provide a single metric of genetic liability that can achieve predictive
performance comparable to traditional clinical risk factors. Current methodologies are undergoing a
paradigm shift, moving beyond simple linear additive models to incorporate complex linkage
disequilibrium (LD) structures, multi-ancestry frameworks, and functional genomic landscapes. In
particular, the integration of regulatory annotations, including expression quantitative trait loci
(eQTL), chromatin accessibility, and cell-type-specific enhancers, has enhanced both the biological
interpretability and predictive robustness of these scores.
This review synthesizes the rapid methodological evolution of PRS, encompassing Bayesian shrinkage
frameworks, machine learning algorithms, and functionally informed strategies designed to mitigate the
persistent Eurocentric biases in current datasets. We critically evaluate the evidence supporting the
integration of PRS into clinical workflows, focusing on cardiovascular diseases, oncology, and
neuropsychiatric disorders, where genetic stratification can enhance preventive interventions and
diagnostic precision. Despite this progress, we identify significant challenges to widespread adoption,
including the reduced portability of scores across diverse populations, the lack of standardized
clinical thresholds, and complex ethical considerations related to health equity.
Finally, we propose a multidisciplinary roadmap for the future of PRS, emphasizing the necessity of
global biobank diversity, dynamic risk modeling that incorporates temporal and environmental factors,
and the seamless integration of genomic insights into electronic health records. Collectively, these
advancements are essential for transitioning PRS from a powerful research tool into an equitable and
actionable component of the precision medicine toolkit.
Keywords: Polygenic risk scores; Genome-wide association studies; Precision medicine; Clinical implementation.
Introduction
The trajectory of human genetics has been fundamentally reshaped by the success of genome-wide association studies (GWAS), which have elucidated the polygenic architecture of complex traits [1]. It is now well established that the genetic liability for most common diseases is not driven by a single high-effect variant but rather by the cumulative contribution of thousands of variants, each exerting subtle effects. Polygenic risk scores (PRS) as a core tool for measuring the genetic susceptibility to complex diseases have played an important role in genomic research [2]. By distilling genome-wide summary statistics into a personalized risk profiles, PRS offer a unique opportunity to identify individuals at the extreme tails of the risk distribution, where the genetic burden may rival the impact of rare, high-penetrance mutations, as observed in conditions such as coronary artery disease (CAD), breast cancer, and type 2 diabetes (T2D) [3-5].
However, the surge of interest in PRS has simultaneously revealed critical systemic bottlenecks that hinder their widespread clinical adoption [6]. Primarily, the predictive accuracy of PRS is inextricably linked to the ancestral composition of the discovery GWAS. The current genomic landscape remains profoundly Eurocentric, creating a portability crisis in which scores developed in European cohorts exhibit diminished performance and, in some cases, complete failure in non-European populations [7-9]. This ascertainment bias not only limits the global utility of genomic medicine but also risks exacerbating existing health disparities. Furthermore, while early PRS relied on simple clumping and thresholding heuristics, the field now demands more statistically rigorous frameworks. Modern Bayesian and machine learning methodologies, such as LDpred2 and SBayesR, have refined effect-size estimation by accounting for complex linkage disequilibrium (LD) structures [10-12]. However, their transition from computational benchmarks to standardized clinical tools remains fragmented.
A parallel revolution in regulatory genomics is now providing the missing link between statistical correlation and biological causation. By integrating multiple omics layers, including expression quantitative trait loci (eQTL), chromatin accessibility profiles, and single-cell regulatory maps, researchers are advancing toward functionally informed PRS [13, 14]. These approaches prioritize variants within causal regulatory elements, thereby enhancing signal-to-noise ratios and potentially improving cross-population portability. Beyond mere prediction, this integration facilitates a mechanistic understanding of how polygenic risk converges on specific tissue types and biological pathways [15].
Despite significant technical progress, the clinical implementation of PRS remains at a crossroads. Formidable challenges persist in establishing clinically actionable risk thresholds, calibrating scores for diverse healthcare settings, and effectively communicating probabilistic risks to both providers and patients [16-18]. As the field advances toward a more mature phase of genomics-informed healthcare, there is a pressing need for frameworks that are not only statistically robust but also biologically grounded and ethically equitable [19].
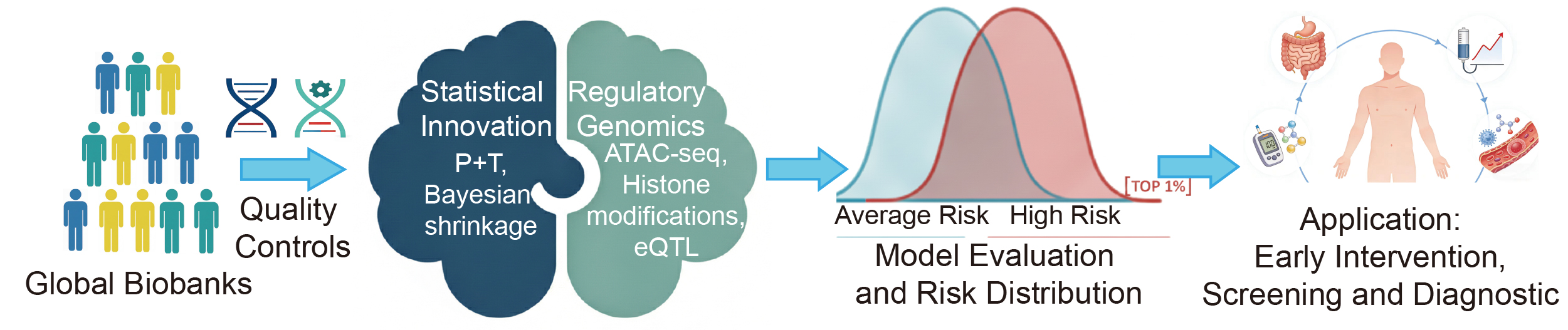
This review offers a comprehensive synthesis of the PRS landscape, tracing its progression from methodological innovation to clinical application. We place particular emphasis on three key pillars: resolving cross-ancestry biases, integrating functional genomics to enhance interpretability, and developing pragmatic strategies required to embed these scores into real-world clinical decision-support systems (Figure 1).
Figure 1. The construction and clinical translation of polygenic risk scores.
Construction of Polygenic Risk Scores
The architecture of a PRS represents a synthesis of genomic discovery and statistical refinement. For each individual, the PRS is computed by summing all SNPs, each weighted by its corresponding effect size. PRS is calculated across a range of P value thresholds, such as PT = 0.0001, 0.0002, ..., 0.05, ..., 0.1, ..., 0.5. The P value threshold, PT, that yields the highest R2 is considered the most predictive cutoff [20]. While the foundational principle, aggregating weighted risk alleles, is straightforward, the transition from raw GWAS summary statistics to a clinically predictive tool involves complex modeling to account for LD, allelic heterogeneity, and ancestral architecture [11, 21]. This section delineates the essential components of PRS construction, highlighting the shift from heuristic-based filtering to sophisticated probabilistic frameworks.
Data Sources and Quality ControlThe accuracy of any PRS is inherently limited by the quality of its underlying GWAS. Modern discovery datasets increasingly utilize large-scale biobanks, such as the UK Biobank, FinnGen, and All of Us, which provide the high-resolution genetic maps necessary for dissecting polygenic traits [22, 23]. However, the effectiveness of PRS depends on both statistical power and ancestral alignment. Rigorous quality control (QC) remains essential to prevent the accumulation of statistical noise. Rare variants with a minor allele frequency (MAF) below 0.01 are traditionally excluded due to unstable effect size estimates, although they represent a promising frontier for sequencing-based PRS [24, 25]. Additionally, stringent filtering for imputation quality (such as INFO score > 0.8) is critical, especially in non-European populations where reference panels are often less optimized, resulting in increased measurement error and reduced predictive power [26].
Statistical Weighting and LD ModelingA central challenge in PRS construction is the deconvolution of LD structures. Because causal variants are often concealed within large blocks of co-inherited SNPs, simple GWAS effect sizes are inherently confounded by the surrounding LD landscape [27].
The first method is heuristic pruning and thresholding (P+T). Early PRS methodologies relied on clumping (r2 < 0.2) and P-value thresholding. While computationally efficient, these approaches often discard informative independent signals and fail to capture the cumulative contribution of sub-significant loci, which are critical for highly polygenic traits. The second method involves Bayesian shrinkage and joint modeling. To overcome the limitations of P+T, contemporary frameworks employ Bayesian shrinkage techniques (such as LDpred2 and PRS-CS) or penalized regression methods (such as LassoSum) [28]. These methods utilize external LD reference panels to model the posterior distribution of effect sizes, effectively shrinking the effects of SNPs in high-LD regions to mitigate overestimation. These models significantly outperform P+T in capturing the heritability of complex phenotypes [10, 29].
The Role of Functional PriorsPerhaps the most significant advancement in PRS construction is the shift from biology-agnostic models to functionally informed frameworks. Instead of treating all SNPs equally, methods such as PolyFun-PRS and AnnoPred utilize functional genomic data, including chromatin accessibility (ATAC-seq), histone modifications (such as H3K27ac), and eQTL profiles, to assign informed priors to genetic variants [30, 31]. By prioritizing variants located within cell-type-specific regulatory elements, these models not only improve predictive accuracy but also establish a mechanistic link between non-coding variation and disease pathophysiology [32].
Evaluating Model PerformanceThe validation of a PRS requires more than a simple correlation. It necessitates a multidimensional assessment, including: (1) Discrimination, evaluated using the area under the receiver operating characteristic curve (AUROC) or the C-index for time-to-event data [33]. (2) Calibration, which ensures that the predicted probability of disease aligns with the observed incidence in independent cohorts [34]. (3) Incremental value, which determines whether the PRS provide additional predictive power beyond established clinical risk factors such as age, sex, BMI, and lipid profiles [35].
Clinical Applications: From Risk Prediction to Precision Intervention
Despite promising predictive performance, the real-world clinical benefit of PRS-guided interventions remains under active investigation, and large-scale prospective trials are still limited. The clinical translation of PRS represents a shift toward a genomics-first approach in preventative medicine. While traditional clinical risk factors, such as blood pressure, lipid profiles, family history, reflect current physiological states, PRS provide a stable, lifelong measure of innate genetic liability [36]. This section evaluates the evidence supporting PRS across major disease domains, emphasizing its role in enhancing risk stratification and guiding personalized clinical decision-support systems.
Firstly, cardiovascular disease, particularly CAD, serves as the prototype for PRS-informed healthcare [37]. Large-scale biobank studies have demonstrated that individuals in the top 0.5% to 1% of the PRS distribution have a disease risk comparable to those with monogenic mutations, such as familial hypercholesterolemia [38]. Importantly, PRS can identify this high-risk group among individuals with normal LDL-C levels, who would otherwise be missed by traditional screening protocols [39, 40]. The clinical utility of CAD PRS is further supported by evidence showing that individuals at high genetic risk derive a greater absolute benefit from statin therapy, regardless of their baseline clinical risk [41]. This establishes a clear pathway for precision prevention, where genetic markers can justify earlier or more intensive pharmacological interventions.
In oncology, PRS are increasingly integrated into risk-stratification models to optimize the timing and frequency of cancer screening. Individuals with high PRS (top 1%) exhibit a 4- to 6-fold increased risk of breast cancer, comparable to that conferred by moderate-penetrance variants [16]. Integrating PRS with traditional models has been shown to refine the recommended starting age for mammography, potentially reducing the burden of over-screening in low-risk individuals while intensifying surveillance for those who are genetically vulnerable [4, 42]. A significant advancement in oncology is the use of polygenic modulation to better understand monogenic risk. PRS can explain the incomplete penetrance of high-risk variants, such as BRCA1 and BRCA2, providing a more nuanced and individualized risk estimate that is essential for surgical counseling and long-term surveillance [43].
When referring to T2D and obesity, PRS provide early-life insights that precede the manifestation of metabolic biomarkers [44]. PRS can predict T2D risk decades before the onset of hyperglycemia. Evidence from the Diabetes Prevention Program suggests that individuals with a high genetic risk may experience enhanced benefits from intensive lifestyle modifications or early metformin intervention, indicating the potential for genetics-informed lifestyle coaching [39, 45].
Despite challenges posed by phenotypic heterogeneity, PRS provide critical support in psychiatric diagnostics and neurodegenerative risk assessment [46]. In psychiatry, PRS have shown promise in differentiating between schizophrenia and bipolar disorder during early-stage psychosis, where clinical presentations often overlap [47]. The transition from static PRS to polygenic hazard scores (PHS), which incorporate age-dependent risk, has revolutionized the prediction of Alzheimer's disease (AD) onset [48]. PHS correlate strongly with cerebrospinal fluid (CSF) biomarkers, such as amyloid-β and tau, and brain atrophy, providing a valuable tool for stratifying participants in clinical trials of disease-modifying therapies [49, 50].
Beyond risk prediction, PRS are increasingly used to refine the interpretation of rare variants and to predict drug responses [51]. Recent evidence suggests that the clinical severity of many monogenic conditions, such as cardiomyopathies, is significantly influenced by the polygenic background, supporting a polygenic modifier model that improves the accuracy of variant classification [52].
Challenges and Limitations: Navigating the Obstacles to Clinical Utility
Despite the rapid advancement of PRS methodologies, several fundamental barriers, ranging from ancestral disparities to methodological opacity, must be addressed to ensure their safe and equitable deployment. These challenges can be categorized into three critical dimensions: including ancestral portability, biological complexity, and implementation ethics (Table 1).
When considering ancestral portability, the most significant limitation of current PRS is the Eurocentric ascertainment bias. Since the majority of discovery GWAS are conducted in individuals of European descent, the resulting scores often fail to generalize to global populations [7, 8]. For example, predictive performance can decrease substantially in non-European cohorts, such as a 4-fold reduction in CAD-PRS accuracy in African populations. This decline is driven by divergent LD patterns, differences in allele frequencies, and heterogeneous gene-environment interactions [53]. Applying these biased scores in clinical settings without cross-ancestry calibration risks exacerbating existing health disparities, effectively creating a genomic divide between populations [54].
Regarding biological complexity, although Bayesian and machine learning models have enhanced statistical calibration, significant gaps remain in fully capturing the genetic architecture of complex traits. Current PRS typically account for only a fraction of the narrow-sense heritability [55]. The missing heritability is likely hidden in rare variants, structural variations, and complex epistatic interactions that are inadequately captured by SNP-based microarrays [56, 57]. Traditional PRS provide only a snapshot of genetic risk and often overlook the temporal dynamics of disease, such as age-dependent penetrance, and the longitudinal accumulation of risk influenced by changing environmental exposures [58].
Regarding implementation ethics, the transition from a statistical probability to a clinical diagnosis involves complex sociotechnical challenges. PRS are inherently probabilistic, not deterministic [59]. Misinterpreting a high-percentile score as an inevitable diagnosis can lead to psychological distress or unnecessary medical procedures, while a low score may foster a false sense of security [16, 17]. Currently, there is a paucity of standardized frameworks for clinical validation, reporting, and integration into electronic health records. Without rigorous regulatory oversight and consensus on risk thresholds, the utility of PRS remains inconsistent across different healthcare systems [60].
Table 1. Challenges and Solutions in the Clinical Application of PRS.
| Dimension | Key Challenges and Bottlenecks | Proposed Strategic Solutions |
|---|---|---|
| Equity and Diversity | Eurocentric ascertainment bias: attenuated portability in non-European populations due to divergent LD and allele frequencies. | Expand global biobank diversity and implement multi-ancestry Bayesian frameworks. |
| Biological Depth | Black box additivity: additive models ignore non-linear epistasis, gene-environment interactions, and rare variants. | Integrate single-cell regulatory maps and proteomic data and utilize explainable AI to map risk to specific biological pathways. |
| Clinical Utility | Lack of standardization: absence of consensus on risk thresholds, reporting formats. | Establish international polygenic risk reporting standards. |
| Temporal Dynamics | Static risk snapshot: conventional PRS fail to account for age-dependent penetrance and cumulative environmental risk. | Develop polygenic hazard scores that integrate age and biomarkers into dynamic, life-course risk trajectories. |
| Ethical and Social | Psychosocial impact: risk of fatalism, misinterpretation of probabilistic data, and insurance discrimination. | Develop genetic counseling toolkits and implement regulatory frameworks to protect genomic privacy and prevent bias. |
Future Directions: A Roadmap to Next-Generation Precision Medicine
To transition PRS from an experimental metric to a cornerstone of genomic medicine, the field must undergo a multidisciplinary evolution characterized by biological depth, algorithmic transparency, and global inclusivity.
The first topic concerns decolonizing genomics and promoting multi-ancestry innovation. The priority for the next decade should be the globalization of genomic discovery. Initiatives such as H3Africa, the Mexico City Prospective Study, and the All of Us are essential for building diverse reference panels [61, 62]. Future algorithms, including next-generation PRS-CSx, must better leverage shared genetic architectures while explicitly modeling population-specific LD and environmental contexts to achieve equitable portability [63].
The second future direction involves functionally informed and multi-omic integration. We anticipate a shift from biology-agnostic SNPs to mechanistically grounded risk profiles. Integrating single-cell regulatory maps and spatial transcriptomics will enable PRS to prioritize variants with high functional impact in disease-relevant tissues, such as microglia in AD or cardiomyocytes in CAD [64, 65]. Combining PRS with real-time proteomic and metabolomic data will facilitate a dynamic risk framework that captures the interplay between stable genetic liability and fluctuating biological states [66].
The third area concerns deep learning and AI. While linear additive models have traditionally been the foundation of PRS, deep learning approaches, such as graph neural networks and transformers, offer the potential to capture non-linear epistatic effects and complex structural variations [67, 68]. However, the emphasis must remain on explainable AI to ensure that these black-box models provide clinicians with interpretable biological pathways rather than merely a numerical score [69].
The ultimate goal is the seamless integration of PRS into real-world clinical decision-support systems. The future development of PRS will focus on dynamic and multidisciplinary integration, combining longitudinal environmental data, multi-omics information, and interpretable AI technologies to achieve individualized life cycle risk assessment [70]. Developing international guidelines for the polygenic risk reporting, comparable to standard lipid panels, is essential for clinician education and patient empowerment [71].
Conclusion and Future Perspectives
PRS have catalyzed a paradigm shift in genomic medicine, evolving from theoretical constructs into quantitative tools capable of deciphering the inherited architecture of complex diseases [72]. By aggregating signals from millions of common variants, PRS provide a unique metric of genetic liability that complements traditional clinical biomarkers, offering insights into personalized disease prevention and biologically informed diagnostics [73]. Over the past decade, this field has experienced exponential growth, driven by the integration of functional genomics, pleiotropic frameworks, and machine learning methodologies, all of which have progressively enhanced both the predictive accuracy and the mechanistic interpretability of these scores [74, 75].
However, the path toward widespread clinical adoption is marked by significant systemic challenges. PRS remain probabilistic estimates rather than definitive diagnoses, and their predictive capacity is currently limited by the missing heritability contained in rare variants, structural variations, and complex interactions [57]. Perhaps most critically, the Eurocentric ascertainment bias present in existing genomic datasets constitutes a major bottleneck. Without the rigorous development of multi-ancestry reference panels and trans-ancestry modeling, the clinical implementation of PRS risks inadvertently exacerbating global health disparities [7, 53]. Furthermore, transitioning to real-world healthcare applications requires addressing complex ethical and regulatory challenges, including standardized risk communication, data privacy, and the establishment of robust clinical decision-support systems [16, 18].
The next frontier of PRS lies in their dynamic and multidisciplinary integration. By harnessing longitudinal environmental data, multi-omic layers, and explainable AI, the field is advancing toward life-course risk trajectories, dynamic assessments that evolve as an individual age [76]. Achieving this vision requires a concerted effort to decolonize genomics, ensuring that the benefits of precision medicine are accessible across all ancestral backgrounds.
In conclusion, PRS represent a fundamental pillar of the next generation of precision medicine. Their transformative potential, however, depends on a synergistic commitment to methodological rigor, clinical utility, and social equity. Only through close interdisciplinary collaboration among geneticists, clinicians, bioinformaticians, and policymakers can we bridge the gap between genomic discovery and impactful public health outcomes, ultimately materializing the promise of polygenic prediction into a global clinical reality.
Abbreviations
PRS: polygenic risk scores; GWAS: genome-wide association studies; eQTL: expression quantitative trait loci; CAD: coronary artery disease; T2D: type 2 diabetes; LD: linkage disequilibrium; MAF: minor allele frequency; HWE: hardy-weinberg equilibrium; CVD: cardiovascular diseases; FH: familial hypercholesterol-emia; LDL: low-density lipoprotein; AD: alzheimer’s disease; PHS: polygenic hazard scores; DPP: diabetes prevention pro-gram; EHR: electronic health records; MCI: mild cognitive im-pairment; AI: artificial intelligence.
Declarations
Acknowledgements
This research was supported by Wenzhou Key Laboratory of Health Big Data and Translational Medicine.
Author Contributions
Tao Wang and Jun Li collected and analyzed the literature, and wrote the initial manuscript. Yinghao Yao and Xing Zheng made contributions to the study design, modifying the man-uscript. All authors collected the literature and endorsed the manuscript's final version.
Funding information
This work was supported by the General Project of Zhejiang Provincial Education Department (Y202559997).
Ethics Approval and Consent to Participate
Not Applicable.
Competing Interests
The authors declare no competing interests.
Data availability
Not Applicable.
References
 Figures
Figures References
References Peer
Peer Information
InformationFigure 1. The construction and clinical translation of polygenic risk scores.
Peer-review Terminology
Identity transparency: Single anonymized
Reviewer interacts with: Editor
Details
This is an open access article under the terms of the Creative Commons Attribution License(http://creativecommons.org/licenses/by/4.0/), which permits use, distribution and reproduction in any medium, provided the original work is properly cited.
Publication History
Received 2025-11-23
Accepted 2025-03-01
Published 2025-03-17